Universities: Graz University of Technology, The George Washington University, American University
Supervisor: Krzysztof Pietroszek, Christian Gütl
Thesis: Visual Interaction Using Augmented Reality for Remote Assistance and Training in Procedural Tasks
We live in a world where access to services such as health care and education are not equally distributed. Only a small number of the world’s population has access to highly skilled service individuals. Technological advancement can help resolve this inequality by making services easily accessible and available to larger parts of the world’s population.
By developing more capable, individualized, and task-specific telecommunication technology, remote access to specific services can be made available. When domain specialists have to choose between receiving video-conferencing-based versus in-person assistance, most people prefer in-person, especially when facing challenging procedural tasks. This applies to both training and emergency assistance. The reason is that video-conferencing technology does not provide adequate collaboration capabilities. A human-centered technology could support specific needs to express themselves. The technology must be application- and procedure-specific to be useful for remote assistance when facing challenging procedural tasks. State-of-the-art video-conferencing technology is generic and facilitates accessibility and operability but does not work sufficiently for many different applications. Spatial information, haptic perception, and other means of communication, \ie spatial visual communication, are required for remote procedural assistance and training.
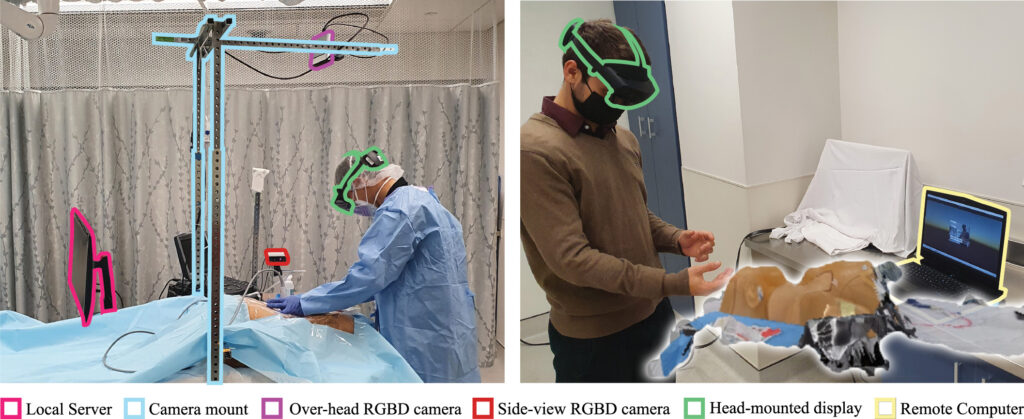
We propose the design and development of an augmented reality (AR) collaboration system for remote assistance and training in procedural tasks. The system captures and transmits the environment spatially and, thus, allows for spatial collaboration. Moreover, the system supports hand-free operation, verbal and non-verbal communication including gestures, and visual communication including procedure-specific 3D models.
We evaluated this AR collaboration system in two primary user studies focusing on health care applications. The first user study assessed medical training through AR, while the second investigated emergency assistance. Instruments for assessment included objective performance measures, cognitive load surveys, AR surveys, and open-ended questions.
The results of this research contain effective strategies for designing procedure-specific AR collaboration systems. Moreover, we presented methods of teaching procedural skills in AR. Despite the novelty of the AR technology for the participants of the study and their inexperience with the technology, the cognitive load and performance of users did not change significantly.
The newly explored AR collaboration design principles and teaching strategies can be applied to remote assistance and training in different applications. The research has shown that AR technology can be used even in challenging and critical environments such as health care. Furthermore, the research presents a step towards the broader adoption of the technology for remote procedural skill training and emergency assistance. Most importantly, AR collaboration technology will make high-quality procedural assistance more accessible and affordable.
Augmented Reality; Computer Vision; Mixed Reality; Human Computer Interaction; Machine Learning; Artificial Intelligence; 3D Scene Reconstruction; Volumetric Capture; Telehealth; AR Collaboration; Remote Assistance