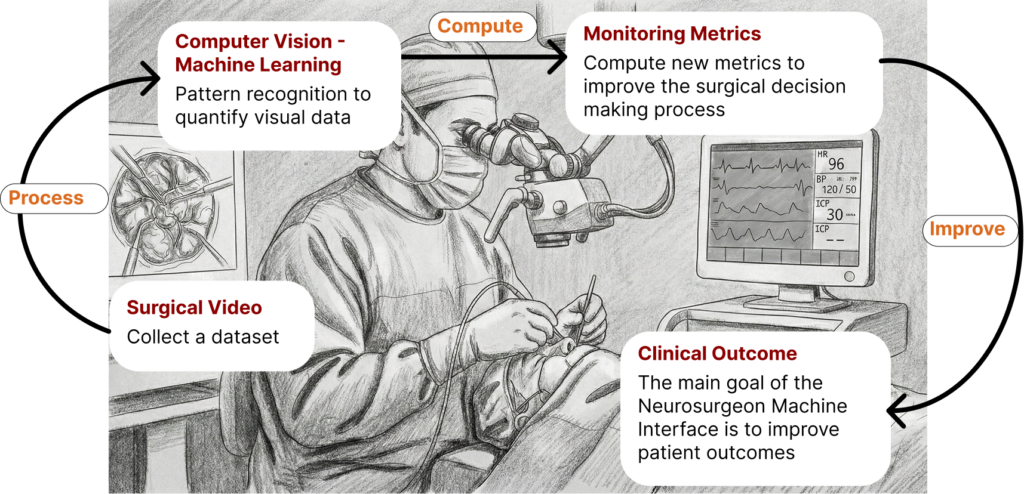
The Neurosurgeon Machine Interface
[SIMI Lab]
Combine machine learning and computer vision to perfect human-AI collaboration

I am an interdisciplinary engineer and innovator, driven by action and motivated by impact. I choose projects based on their potential to create meaningful change.
I favor product-driven, disruptive initiatives with strong commercialization potential. My expertise spans computer vision, artificial intelligence, and augmented reality.
I am deeply fascinated by the human visual system and its fundamental role in how we perceive and interact with the world. My work focuses on closing the gap between human and machine image understanding through artificial intelligence. Bridging this gap is a critical step toward artificial general intelligence (AGI). With this goal in mind, I actively work on multi-modal AI, human-in-the-loop supervised learning, reinforcement learning, and meta-learning.
Looking ahead, I aim to expand my scope from visual intelligence and perception toward physical intelligence, bringing intelligent systems closer to real-world interaction and embodiment.
Ultimately, I aspire to work on the challenges that emerge in a world where artificial intelligence has surpassed human-level intelligence.
[SIMI Lab]
ByteDance’s Pico 4 Ultra headset offers SecureMR, a framework that enables on-device AI model execution. This allows sensitive data, such as first-person video, to be processed locally and securely without leaving the device. As a result, the platform opens up significant opportunities for applications in healthcare, where privacy and data protection are critical.
As a demonstration use case, we developed Glucose MR, an application designed to support people with diabetes in everyday decision-making. The app provides real-time assistance by analyzing a user’s environment and helping them make informed choices about what food to eat or order.
[Github]
The strength of the parent-child relationship is critical to a child’s social and emotional development. And yet, today there is a breakdown in family communication. Over 150 million parents are anxious that the bonds with their children are deteriorating. Today, 2 in 5 kids lack an emotional bond with their parents, and 50% of those kids suffer mental health challenges as a result.
Our approach to spatial journaling incorporates GenAI and WebXR, meaning it uses speech-to-3D, is device agnostic, and multiplayer. It is a collaborative, gamified journaling experience. Not only do parents and children engage in meaningful conversation, but they co-create 3D assets that can be saved (and revisited) and visually represent their memories in XR.

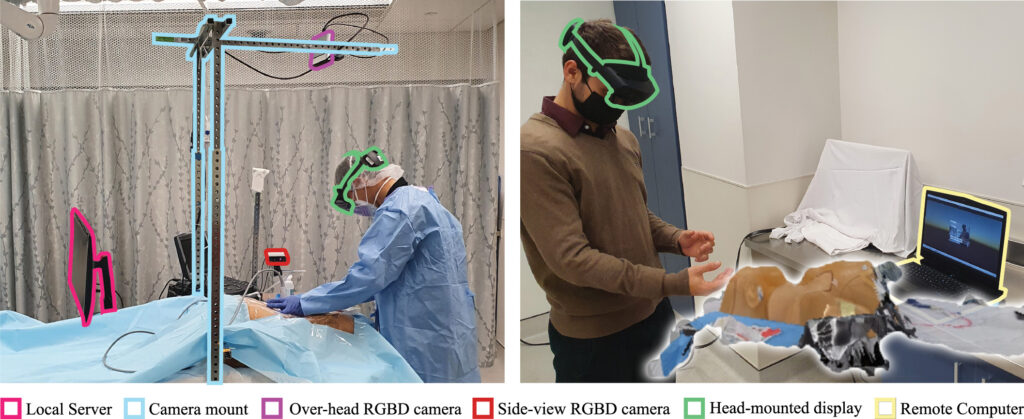
Medical procedures are an essential part of healthcare delivery, and the acquisition of procedural skills is a critical component of medical education. Unfortunately, procedural skill is not evenly distributed among medical providers. We present a mixed reality real-time communication system to increase access to procedural skill training and to improve remote emergency assistance. Our system allows a remote expert to guide a local operator through a medical procedure.
We design and evaluate a mixed reality real-time communication system for remote assistance during CPR emergencies. Our system allows an expert to guide a first responder, remotely, on how to give first aid. RGBD cameras capture a volumetric view of the local scene including the patient, the first responder, and the environment. The volumetric capture is augmented onto the remote expert’s view to spatially guide the first responder using visual and verbal instructions. We evaluate the mixed reality communication system in a research study in which participants face a simulated emergency. The first responder moves the patient to the recovery position and performs chest compressions as well as mouth-to-mask ventilation. Our study compares mixed reality against videoconferencing-based assistance using CPR performance measures, cognitive workload surveys, and semi-structured interviews. We find that more visual communication including gestures and objects is used by the remote expert when assisting in mixed reality compared to videoconferencing. Moreover, the performance and the workload for the first responder during simulation does not differ significantly between the two technologies.
Sport practicing through video can be challenging because of missing spatial information. Hence, we present a holographic sports library of short sports exercises that are used to practice sports. The
sports holograms were captured in a volumetric recording studio. Users can watch the holograms on augmented reality (AR) devices such as mobile phones and headsets. The user can take advantage
of the spatial information and watch the holograms from multiple different angles. Moreover, the user can step in and imitate

We present an augmented reality (AR) system for remote digital health coaching. Patients who are unable to commute to the clinic, or to digital literacy classes, but still require individual training can be taught remotely using AR technology. Additionally, coaching services offered in clinic settings can be distributed so that the coach can be virtualized. Compared to video conferencing, AR offers a more intuitive spatial communication. Therefore, a close to in-person coaching experience is possible.

We describe three interactive augmented reality stories for children that we showed at the Cannes Film Festival “Marche du Film” in July 2021. The stories were developed using a novel technique: 3D modeling and animation from within the Virtual Reality. The audience at Cannes viewed and interacted with these stories using mixed reality glasses, a prototype of the Sony Spatial Display, and an AR-enabled tablet. We report on the technical development process and the feedback from the Cannes audience.
Streptococcus pharyngitis, or strep throat, is a very common reason for ambulatory care visits in the States annually. Early and accurate detection of strep throat helps improve outcomes and minimize complications. Currently, the Centor criteria, a set of validated clinical decision rules, widely used by clinicians to guide management. It is anticipated that medical care will more frequently be delivered by telehealth during and following the COVID-19 pandemic, requiring novel approaches to disease diagnosis. To enhance the applicability and potential diagnostic capability of the Centor score, our goal is to study a machine learning algorithm that pairs the elements of the Centor score with images, videos, and audio recordings of throats to determine whether the patient has streptococcal pharyngitis.
Team: Manuel Rebol, Irena R., Christian G., Krzysztof P., Volker S., Tobias S.
We propose a real-time system for synthesizing gestures directly from speech. Our data-driven approach is based on Generative Adversarial Neural Networks to model the speech-gesture relationship. We utilize the large amount of speaker video data available online to train our 3D gesture model. Our model generates speaker-specific gestures by taking consecutive audio input chunks of two seconds in length. We animate the predicted gestures on a virtual avatar. We achieve a delay below three seconds between the time of audio input and gesture animation.

Non-verbal signals impact the meaning of the spoken utterance in an abundance of ways. An absence of non-verbal signals impoverishes the process of communication. Yet, when users are represented as avatars, it is difficult to translate non-verbal signals along with the speech into the virtual world without specialized motion-capture hardware.

Create your individual unique sliding puzzle with one of your videos. Enjoy the additional challenge of solving a puzzle in which the surface of the tiles is changing.
Upload your own video puzzle and challenge your friends in the multiplayer mode. Compete to find out who can complete the puzzle fastest.

Many semantic segmentation algorithms process images individually which leads to an inconsistent scene interpretation due to illumination changes, occlusions and other variations over time. We train a convolutional neural network (CNN) which propagates features through consecutive frames in a video using a convolutional long short term memory (ConvLSTM) cell to achieve a temporally coherent prediction.
Universities: Graz University of Technology, The George Washington University, American University
Supervisor: Krzysztof Pietroszek, Christian Gütl
Thesis: Visual Interaction Using Augmented Reality for Remote Assistance and Training in Procedural Tasks
By developing more capable, individualized, and task-specific telecommunication technology, remote access to specific services can be made available. When domain specialists have to choose between receiving video-conferencing-based versus in-person assistance, most people prefer in-person, especially when facing challenging procedural tasks. This applies to both training and emergency assistance. The reason is that video-conferencing technology does not provide adequate collaboration capabilities. A human-centered technology could support specific needs to express themselves. The technology must be application- and procedure-specific to be useful for remote assistance when facing challenging procedural tasks. State-of-the-art video-conferencing technology is generic and facilitates accessibility and operability but does not work sufficiently for many different applications. Spatial information, haptic perception, and other means of communication, \ie spatial visual communication, are required for remote procedural assistance and training.
We propose the design and development of an augmented reality (AR) collaboration system for remote assistance and training in procedural tasks. The system captures and transmits the environment spatially and, thus, allows for spatial collaboration. Moreover, the system supports hand-free operation, verbal and non-verbal communication including gestures, and visual communication including procedure-specific 3D models.
We evaluated this AR collaboration system in two primary user studies focusing on health care applications. The first user study assessed medical training through AR, while the second investigated emergency assistance. Instruments for assessment included objective performance measures, cognitive load surveys, AR surveys, and open-ended questions.
The results of this research contain effective strategies for designing procedure-specific AR collaboration systems. Moreover, we presented methods of teaching procedural skills in AR. Despite the novelty of the AR technology for the participants of the study and their inexperience with the technology, the cognitive load and performance of users did not change significantly.
The newly explored AR collaboration design principles and teaching strategies can be applied to remote assistance and training in different applications. The research has shown that AR technology can be used even in challenging and critical environments such as health care. Furthermore, the research presents a step towards the broader adoption of the technology for remote procedural skill training and emergency assistance. Most importantly, AR collaboration technology will make high-quality procedural assistance more accessible and affordable.
Universities: Graz University of Technology, American University
Thesis: Generating Non-Verbal Communication From Speech
Supervisor: Krzysztof Pietroszek, Christian Gütl
We model the non-deterministic relationship between speech and gestures with a Generative Adversarial Network (GAN). Inside the GAN, a motion discriminator forces the generator to predict only gestures that have human-like motion. To provide data for our model, we extract the gestures from in-the-wild videos using 3D human pose estimation algorithms. This allows us to automatically create a large speaker-specific dataset despite the lack of motion capture data.
We train our gesture model on speakers from show business and academia using publicly available video data. Once generated by our GAN, we animate the gestures on a virtual character. We evaluate the generated gestures by conducting a human user study. In the study, we compare our predictions with the original gestures and predictions from uncorrelated speech in two different tasks.
The results show that our generated gestures are indistinguishable from the original gestures when animated on a virtual character. In 53 % of the cases, participants found our generated gestures to be more natural compared to the original gestures. When compared with gestures from an uncorrelated speech, participants selected our gestures to be more correlated 65 % of times. Moreover, we show that our model performs well on speakers from both show business and academia.
University: Graz University of Technology
Thesis: Frame-to-Frame Consistent Semantic Segmentation
Supervisor: Thomas Pock
Advisor: Patrick Knöbelreiter
In this thesis we tackle this problem by training a convolutional neural network (CNN) to perform frame-to-frame consistent semantic segmentation. We use a prediction oracle to create missing ground-truth labels for video data together with a synthetic video data set to train our model. In order to propagate features through the different time steps in a scene, we implement recurrent convolutional layers. More precisely, we use long short term memory (LSTM) and convolutions over the time dimension. Besides the temporal feature propagation, we also add an inconsistency penalty to the loss function which enforces
frame-to-frame consistent prediction. The methods are evaluated with a newly created VSSNet architecture as well as on the state-of-the art ESPNet architecture.
Results show that the performance improves for the VSSNet and for the ESPNet when utilizing video information compared to single frame prediction. We evaluate our models on the Cityscapes validation dataset. The mean intersection over union (mIoU) on the 19 classes of the Cityscapes dataset increases from 44.0 % on single frame images to 56.5 % on video data for the ESPNet. When using an LSTM to propagate features trough time, mIoU raises to 57.9 % while inconsistencies decrease from 2.4 % to 1.3 % which is an improvement by 46.0 %.
The presented results suggest that the added temporal information gives frame-to-frame consistent and more accurate image understanding compared to single frame processing. This ensures that CNN architectures with few parameters and low computational effort are already able to predict scenes accurately.
University: Graz University of Technology
Thesis: Automatic Classification of Business Intent on Social Platforms
Supervisor: Roman Kern
The aim of this thesis is to first detect business intent in the different types of information users post on the internet. In a second step, the identified business intent is grouped into the two classes: buyers and sellers. This supports the idea of linking the two groups.
Machine learning algorithms are used for classification. All the necessary data, which is needed to train the classifiers is retrieved and preprocessed using a Python tool which was developed. The data was taken from the web platforms Twitter and HolidayCheck.
Results show that classification works accurately when focusing on a specific platform and domain. On Twitter 96 % of test data is classified correctly whereas on HolidayCheck the degree of accuracy reaches 67 %. When considering cross-platform multiclass classification, the scores drop to 50 %. Although individual scores increase up to 95 % when performing binary classification, the findings suggest that features need to be improved further in order to achieve acceptable accuracy for cross-platform multiclass classification.
The challenge for future work is to fully link buyers and sellers automatically. This would create business opportunities without the need for parties to know about each other beforehand.
University: Graz University of Technology
Thesis: Automatic Classification of Business Intent on Social Platforms
Supervisor: Roman Kern
School: HTBLA Kaindorf
Thesis: Business Process Management Optimization – The BPM Extended Game
Supervisor: Walter Pobaschnig, Heike Eder-Skoff, Johann Wurzinger
The aim of this research thesis was to find a way to simplify business processes as well as modeling them since this topic is very complex and students usually find it difficult to understand.
In order to explain how business processes in a company might look like, a board game was developed, in which the player learns, while playing the game. The game teaches the different business processes of an e-bike rental company.
Result showed that the idea of explaining business processes by using a board game is quite efficient and learners do not only notice how business processes might look like, but also had a lot
of fun playing the game.
There might be challenges and chances in the future in the sector of business processes, because the trend is that companies try to operate business processes not only efficiently, but also sustainably and economically. Business processes should run as “green” as possible.